파일 다운로드하기
지금부터 공공데이터포털에서 파일을 다운받는 방법에 대해 알려드리겠습니다. 대표적으로 2가지의 방법이 있습니다. (사실 정확히 몇 가지인지 잘 모름ㅎㅎ) 바로 request와 wget을 이용하는 겁니다. 처음 request를 사용하다가 wget으로 변경하였습니다. 오늘은 이 2가지의 방법에 대해 설명을 하면서 왜 wget으로 변경하게 되었는지 알려드리겠습니다.
이 전 글에서 파일을 다운로드하는데 필요한 2가지 uddi, publicDataPk를 추출하는 방법에 대해 게시하였습니다. 사실 정확히 말하자면 파일을 다운로드 하기위해 필요한 atchFileId을 구하기 위해 uddi와 publicDataPk가 필요한겁니다.
공공데이터포털에서 파일데이터를 다운받고 dev tools로 확인하시면 아래와 같은 url로 request를 하는것을 알 수 있는데 jsonObj를 response 받게 됩니다.
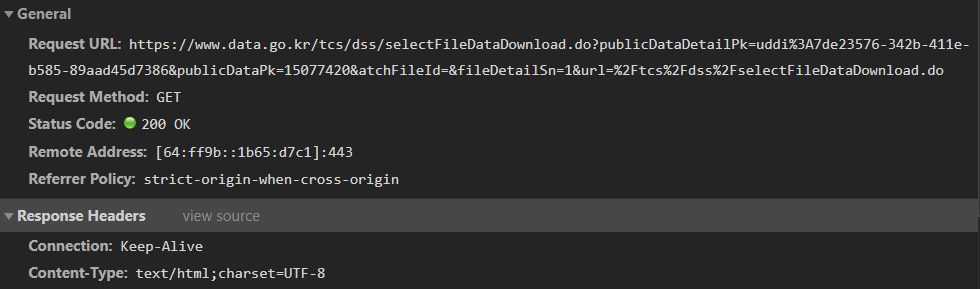

dev tools를 이용하여 파일을 다운하는데 js function이 어떻게 작동하는지 열심히 보시면... js/biz/cmm/cmm/script_cmmFunction.js에 fn_fileDownload() 에서 파일을 다운받을 수 있는것을 확인할 수 있습니다.
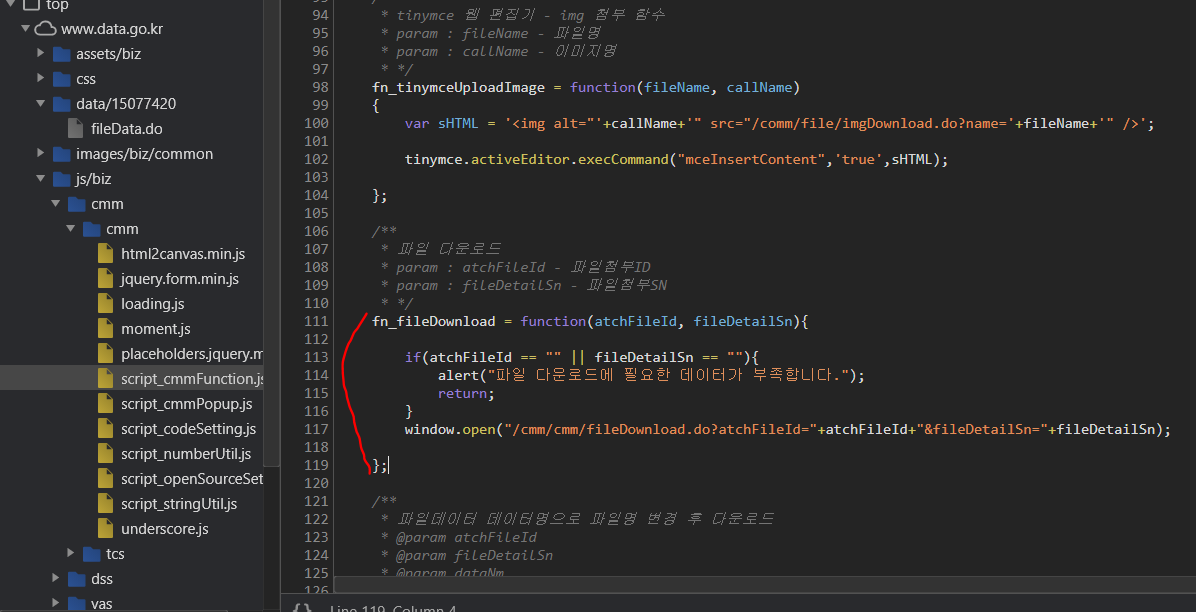
이제 우리는 json 형태의 자료에서 atchFileId를 추출하여 request를 하면 됩니다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
|
def getDownLoad(publicDataPk, title, uddi):
url = "https://www.data.go.kr/tcs/dss/selectFileDataDownload.do?publicDataDetailPk=uddi%3A"
url += uddi
url += "&publicDataPk="
url += publicDataPk
url += "&atchFileId=&fileDetailSn=1&url=%2Ftcs%2Fdss%2FselectFileDataDownload.do"
try:
jsonObj = ""
try:
jsonObj = requests.get(url, verify=False, timeout=25).json()
except (Exception, requests.exceptions.Timeout, requests.exceptions.ConnectTimeout) as err:
stop(err)
jsonObj = requests.get(url, verify=False, timeout=25).json()
atchFileId = jsonObj['atchFileId']
except json.decoder.JSONDecodeError as err:
print("downLoad error : " + publicDataPk + " " + title, err)
return "downLoad error"
else:
if atchFileId is None:
return "N"
result = "https://www.data.go.kr/cmm/cmm/fileDownload.do?atchFileId="
result += atchFileId
result += "&fileDetailSn=1"
|
cs |
먼저 uddi와 publicDataPk를 이용하여 url을 만들어서 requests.get()을 이용하여 jsonObj로 return 받습니다.
이 때 verify=False 옵션은 SSL 오류 발생을 방지하는 옵션이고 timeout=25는 timeout을 25초로 하겠다는 옵션입니다.
그리고 jsonObj에서 atchFileId를 추출하면 됩니다. 11라인을 보시면 예외가 발생하면 stop()을 호출하고 다시 jsonObj를 실행하는데 사실 여기에서 예외가 발생한적은 아직 없지만 혹시 서버에 부하가 발생하여 timeout이 발생하거나 다른 예외가 발생할 경우 잠시 크롤링을 멈추고 다시 시도해보자 라는 생각으로 코드를 작성하였습니다.
18라인은 atchFileId가 없는 경우가 있어서 예외처리하였습니다. 그리고 atchFileId가 없는 경우는 파일 다운로드 과정을 종료하면서 파일을 다운로드 할 수 없음을 기록하기 위해 return False를 하였습니다.
request를 이용하는 방법
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
fileStreNm = getNewFileId(tmp)
if (extend == "csv") or (extend == "xlsx") or (extend == "xls"):
try:
request.urlretrieve(result, fileStreNm)
except Exception as err:
stop(err)
request.urlretrieve(result, fileStreNm)
else:
try:
request.urlretrieve(result, fileStreNm)
except Exception as err:
stop(err)
request.urlretrieve(result, fileStreNm)
|
cs |
request.urlretrieve()는 저장할 파일 이름을 지정해야 합니다.
저장할 파일이름을 getNewFileId()를 이용하여 파일이름을 지정하였는데 이 부분은 파일을 관리하는 회사 내부 방식으로 공개할 수 없음을 알려드립니다ㅠㅠ
여기서 공공데이터포털의 단점이 하나 나옵니다 바로 웹 화면에 나온 확장자와 실제 파일의 확장자가 다르다 입니다.
분명 csv로 표시되어 있는데 실제로는 zip파일인 경우가 있습니다.(csv 파일 여러개를 압축한 경우) 따라서 request를 이용하여 파일을 다운받기는 한계가 존재합니다.
wget을 이용하는 방법
그렇기 때문에 wget을 사용하여 파일을 다운받은 다음 확장자를 확인해야 합니다.
|
1
2
3
4
5
6
7
8
9
|
try:
ans = wget.download(result)
except Exception as err:
stop(err)
ans = wget.download(result)
os.rename(ans, fileStreNm)
ansList = ans.split(".")
extend = ansList[-1]
|
cs |
wget.download()를 이용하여 다운 받고 다운 받은 결과를 split를 이용하여 확장자를 확인할 수 있습니다. wget을 이용할때 파일명을 지정하는 방법은 os.rename을 이용하여 파일명을 지정하면 됩니다.
'python' 카테고리의 다른 글
| python3와 selenium을 이용하여 javaScript 함수 호출하기 (0) | 2021.12.14 |
|---|---|
| python3으로 CSV 파일 만들기 (0) | 2021.12.14 |
| [공공데이터포털 크롤링] data.go.kr 공공데이터포털 크롤링하기 (3) (0) | 2021.01.24 |
| [공공데이터포털 크롤링] data.go.kr 공공데이터포털 크롤링하기 (2) (0) | 2021.01.24 |
| [공공데이터포털 크롤링] data.go.kr 공공데이터포털 크롤링하기 (1) (0) | 2021.01.10 |




댓글