publicDataPk 구하기
그럼 먼저 url의 숫자 부분인 publicDataPk를 구하도록 하겠습니다.
에 들어가면 교육 카테고리의 목록이 나온다는 것을 이미 (1) 글을 통해 확인하였습니다.
chrome Dev tools를 이용하여 확인을 해보면 공공데이터 포털의 목록들은 li 태그의 집합으로 이루어져 있다는 것을 알 수 있습니다.

정확히는 class명이 result-list인 div 태그 -> ul -> li 태그의 순서로 이루어져 있습니다. 우리는 이 li 태그의 목록을 이용하여 publicDataPk 목록을 구하도록 하겠습니다.
먼저 url을 requests 라이브러리를 이용하여 text 형태로 BeautifulSoup에게 전달하도록 하겠습니다.
get으로 호출할 때 예외가 발생할 수 있으니 예외처리도 하겠습니다. 정확히는 예외가 발생하여도 일정 시간 정지하고 (저는 600초 동안 정지하고 예외 정보를 출력하는 stop 메서드를 만들었습니다.) 하시 시도하도록 코드를 작성하였습니다. 경험적으로 해당 시간 동안 멈추고 다시 시작하여도 정상적으로 작동하였습니다.
|
1
2
3
4
5
6
7
8
9
10
11
|
url = "https://www.data.go.kr/tcs/dss/selectConditionSearch.do?" \
"dType=FILE&brm=교육&sort=updtDt&sort_order=desc&" \
"size=10000¤tPage=1&page=0"
html = ""
try:
html = requests.get(url, verify=False, timeout=25).text
except (Exception, exceptions.Timeout, exceptions.ConnectTimeout) as err:
stop(err)
html = requests.get(url, verify=False, timeout=25).text
soup = BeautifulSoup(html, 'html.parser')
|
cs |
6번째 줄에 보면 verfiy=False, timeout=25가 있는데 각각 SSL를 사용하지 않는다. timeout은 25초로 한다는 옵션입니다.
이제 soup을 이용하여 li 태그에 있는 publicDataPk를 추출하도록 하겠습니다. Dev tools를 이용하여 확인하면 publicDataPk는 a 태그 내부에 href="/data/{publicDataPk}/fileData.do"있습니다.
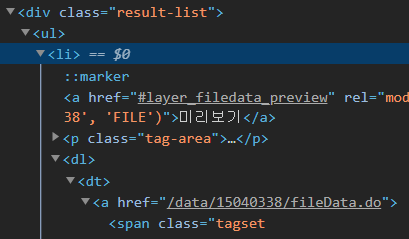
publicDataPk를 구하는 순서는 먼저 li 태그 list를 만들고 iter를 이용하여 publicDataPk를 구할 수 있습니다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
filedatalist = soup.select('div.result-list > ul > li')
tmp = []
for li in filedatalist:
try:
num = li.select_one('dl > dt > a')
except AttributeError as err:
num = "없음"
else:
num = str(num['href'])
num = num.replace("/data/", "")
num = num.replace("/fileData.do", "")
tmp.append(str(num))
|
cs |
혹시 모를 예외를 처리하기 위해 예외처리를 하였고 1번째 줄을 보면 select()를 이용하여 li 태그 목록을 만들었습니다. class 명으로 접근하기 위해서는 (태그명).(class 명)을 이용하면 되고, 그 내부의 태그에 접근하기 위해서는 >로 추가하면 됩니다.
soup는 num ['href'] or num ['onclick']와 같이 이벤트를 접근할 수 있습니다. 접근 후 불필요한 정보는 replace를 이용하여 제거하였습니다.
카테고리 순서대로 publicDataPk list 구하기
자 이제 우리가 원하던 publicDataPk를 구하였습니다. 정확히는 교육 카테고리의 publicDataPk를 구하였습니다. 이제는 카테고리 마다 publicDataPk를 구하도록 하겠습니다. 방법은 크게 어려운게 없습니다.
먼저 카테고리 마다 인코딩 된 url을 list로 만들고 그냥 iter로 하나씩 처리하면 됩니다.
(아래의 소스코드는 지금까지 게시한 글을 바탕으로 작성한 크롤링 소스코드의 일부입니다.)
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
|
import time
def stop(err):
print("------sleep(10m)------")
now = time.localtime()
print("[%02d:%02d:%02d]" % (now.tm_hour, now.tm_min, now.tm_sec))
print(err)
time.sleep(600)
print("----------------------")
def createPublicDataPk(brm):
url = "https://www.data.go.kr/tcs/dss/selectConditionSearch.do?" \
"dType=FILE&brm=" + brm + "&sort=updtDt&sort_order=desc&" \
"size=10000¤tPage=1&page=0"
html = ""
try:
html = requests.get(url, verify=False, timeout=25).text
except (Exception, exceptions.Timeout, exceptions.ConnectTimeout) as err:
stop(err)
html = requests.get(url, verify=False, timeout=25).text
soup = BeautifulSoup(html, 'html.parser')
filedatalist = soup.select('div.result-list > ul > li')
tmp = []
for li in filedatalist:
try:
num = li.select_one('dl > dt > a')
except AttributeError as err:
num = "없음"
else:
num = str(num['href'])
num = num.replace("/data/", "")
num = num.replace("/fileData.do", "")
tmp.append(str(num))
return tmp
if __name__ == "__main__":
list = [
["교육", "%EA%B5%90%EC%9C%A1"],
["국토관리", "%EA%B5%AD%ED%86%A0%EA%B4%80%EB%A6%AC"],
["공공행정", "%EA%B3%B5%EA%B3%B5%ED%96%89%EC%A0%95"],
["재정금융", "%EC%9E%AC%EC%A0%95%EA%B8%88%EC%9C%B5"],
["산업고용", "%EC%82%B0%EC%97%85%EA%B3%A0%EC%9A%A9"],
["사회복지", "%EC%82%AC%ED%9A%8C%EB%B3%B5%EC%A7%80"],
["식품건강", "%EC%8B%9D%ED%92%88%EA%B1%B4%EA%B0%95"],
["문화관광", "%EB%AC%B8%ED%99%94%EA%B4%80%EA%B4%91"],
["보건의료", "%EB%B3%B4%EA%B1%B4%EC%9D%98%EB%A3%8C"],
["재난안전", "%EC%9E%AC%EB%82%9C%EC%95%88%EC%A0%84"],
["교통물류", "%EA%B5%90%ED%86%B5%EB%AC%BC%EB%A5%98"],
["환경기상", "%ED%99%98%EA%B2%BD%EA%B8%B0%EC%83%81"],
["과학기술", "%EA%B3%BC%ED%95%99%EA%B8%B0%EC%88%A0"],
["농축수산", "%EB%86%8D%EC%B6%95%EC%88%98%EC%82%B0"],
["통일외교 안보", "%ED%86%B5%EC%9D%BC%EC%99%B8%EA%B5%90%EC%95%88%EB%B3%B4"],
["법률", "%EB%B2%95%EB%A5%A0"]
]
for brm in list:
time.sleep(10)
publicDataPkList = createPublicDataPk(brm[1])
|
cs |
'python' 카테고리의 다른 글
| [공공데이터포털 크롤링] data.go.kr 공공데이터포털 크롤링하기 (4) (0) | 2021.03.10 |
|---|---|
| [공공데이터포털 크롤링] data.go.kr 공공데이터포털 크롤링하기 (3) (0) | 2021.01.24 |
| [공공데이터포털 크롤링] data.go.kr 공공데이터포털 크롤링하기 (1) (0) | 2021.01.10 |
| python을 이용하여 디렉터리를 생성하고 파일 이동하기 (0) | 2020.06.17 |
| pandas를 이용하여 csv row 추출하기 (0) | 2020.06.11 |



댓글