지금까지 [공공데이터포털 크롤링] data.go.kr 공공데이터포털 크롤링하기(1), (2)를 통해 publicDataPk와 uddi가 있어야 파일을 다운받을 수 있다는 것을 알게되었고, (2) 게시물을 통해 publicDataPk를 구할 수 있었습니다.
그럼 이번에는 uddi를 구하면서 같이 찾을 수 있는 여러 정보에 대해 게시하겠습니다.
publicDataPk를 이용하여 정보 추출하기
아래의 사진은 www.data.go.kr/data/15070713/fileData.do의 화면입니다. 공공데이터포털 파일데이터의 화면분류는 크게 3가지 입니다. 다운로드, 바로가기, 활용신청 (해당 내용은 공공데이터포털의 업데이트 시점에 따라 변경될 수 있음) 이 3가지 정보는 우측 상단의 버튼에 명시되어 있습니다.
- 다운로드 : 파일 다운로드
- 바로가기 : url을 제공하며, 해당 홈페이지로 이동
- 활용신청 : 파일 다운로드와 큰 차이 없음 (업데이트 시 기능 추가될 가능성이 높아 보임)
화면을 보시면 여러 정보들이 있는데 여기서 필요한 정보를 크롤링 하면 됩니다.
저는 다운로드/바로가기 여부, 데이터명, 데이터 내용, 제공기관, 업데이트 주기, 수정날짜, 키워드, 분류체계 등을 크롤링하도록 하겠습니다.

먼저 태그 분석을 통해 해당 데이터의 위치를 파악하겠습니다.

먼저 제목, 데이터 내용, 다운로드 버튼의 정보를 추출하기 위해서 Dev tools로 확인해본 결과
div.data-search-view 내부에 tit-area에서 제목을, cont에서 데이터 내용 그리고 btn-util에서 다운로드 버튼의 정보를 추출할 수 있습니다.
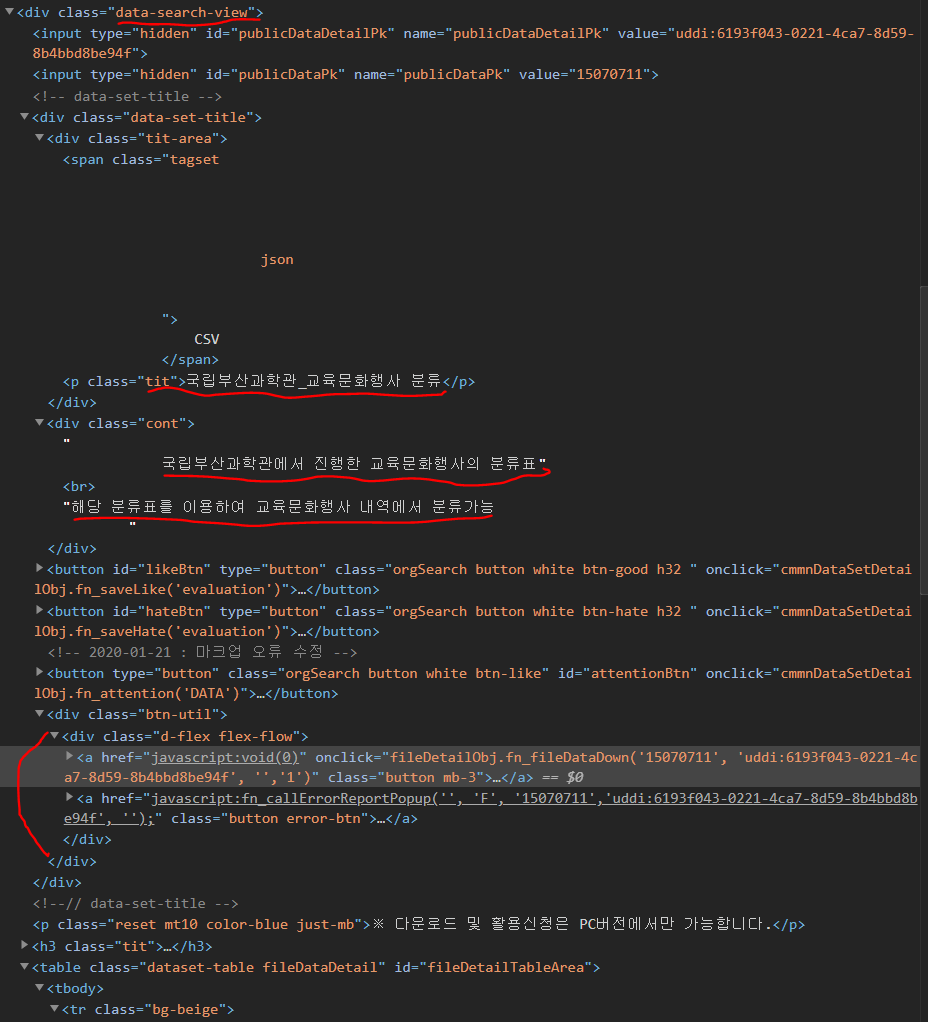
따라서 상위 태그인 data-search-view를 soup.select로 선택하고 select_one을 이용하여 하나씩 선택하여 추출하도록 하겠습니다.
아 그리고 button에서 uddi 를 추출할 수 있습니다! 같이 추출하도록 하겠습니다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
|
# UnboundLocalError: local variable referenced before assignment
# 방지를 위한 선언
extend = title = button = contents = seType = keyWord = uddi = cost = service = \
epoch = modify = name = cont = exam = link = downLoadYN = fileStreNm = ""
filedatalist = soup.select('div.data-search-view')
for i in filedatalist:
# 제목
try:
title = i.select_one('div.data-set-title > div.tit-area > p.tit')
title = title.text.replace('\n', '').strip()
# 제목에 특수문자가 있을 경우 제거
title = title.replace("\t", "")
title = title.replace("\\", "")
title = title.replace("/", "")
title = title.replace(":", "")
title = title.replace("*", "")
title = title.replace("?", "")
title = title.replace('"', "")
title = title.replace("<", "")
title = title.replace(">", "")
title = title.replace("|", "")
except AttributeError as err:
title = "없음"
# 내용
try:
contents = i.select_one('div.data-set-title > div.cont')
contents = contents.text.replace('\n', '').strip()
except AttributeError as err:
contents = "없음"
# 다운로드/바로가기/없음
try:
button = i.select_one('div.data-set-title > div.btn-util > div.d-flex')
uddi = button
button = button.select_one('a')
button = button.text.strip()
link = "없음"
except (AttributeError, KeyError) as err:
button = "활용신청"
if button == "바로가기":
try:
link = uddi.select_one('a')['href']
except (AttributeError, KeyError) as err:
link = "없음"
try:
uddi = uddi.find('a', {'class': 'error-btn'})
uddi = uddi['href']
uddi = uddi.replace("javascript:fn_callErrorReportPopup('', 'F', '"
+ publicDataPk + "','uddi:", "")
uddi = uddi.replace("', '');", "")
except AttributeError as err:
uddi = "없음"
|
cs |
소스코드를 보면 python 특징과 맞지않게 2, 3 line에 먼저 변수를 선언하였습니다.
Dev Tools 결과 사진을 자세히 보시면 데이터 내용에 <br> 태그가 있습니다. 또 가끔씩 제목에 특수문자가 들어가는 경우가 있습니다ㅠㅠ 그래서 replace를 통해 제거하였습니다. 그리고 uddi를 찾을 때 select 말고 find를 이용하여 찾았습니다.
뭐 특별한 이유는 없습니다ㅋㅋㅋ
select와 find의 차이점은 www.inflearn.com/questions/5567를 참고하시길 바랍니다 :)
이번에는 테이블 태그에 있는 정보를 찾아보겠습니다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
|
findTable = soup.find('table', {'id': 'fileDetailTableArea'})
try:
matrix = findTable.find_all('div', {'class': 'td'})
except AttributeError as err:
service = "error"
epoch = "error"
modify = "error"
else:
# for i in range(0, len(matrix)):
# print(i, matrix[i].text.strip())
# for idx, val in enumerate(matrix):
# print(i, matrix[i].text.strip())
try:
service = matrix[2].text.strip()
except AttributeError as err:
service = "없음"
try:
epoch = matrix[7].text.strip()
except AttributeError as err:
epoch = "없음"
try:
extend = matrix[11].text.strip().lower()
extend = extend.replace("*", "")
extend = extend.replace(".", "")
except AttributeError as err:
extend = "없음"
try:
modify = matrix[16].text.strip()
except AttributeError as err:
modify = "없음"
try:
seType = matrix[1].text.strip()
except AttributeError as err:
seType = "없음"
try:
keyWord = matrix[14].text.strip()
except AttributeError as err:
keyWord = "없음"
# publicDataPk, 카테고리, 제목, 확장자, 다운로드/바로가기, 내용, 제공기관, 주기, 수정일,
# 주기성 과거 데이터, 다운로드 여부, 데이터 항목, 데이터 예시
# tmp = [publicDataPk, category, title, extend, button, contents,
# service, epoch, modify, dataHistory, downLoadYN, cont, exam]
tmp = [publicDataPk, category, title, extend, button, contents,
service, epoch, modify, link, seType, keyWord, uddi]
|
cs |
10 line에 보면 for를 이용하여 matrix의 모든 정보를 index와 함께 출력하도록 하였습니다. 둘 중 아무 코드나 사용하셔서 원하시는 정보를 객체로 받으시길 바랍니다.
'python' 카테고리의 다른 글
| python3으로 CSV 파일 만들기 (0) | 2021.12.14 |
|---|---|
| [공공데이터포털 크롤링] data.go.kr 공공데이터포털 크롤링하기 (4) (0) | 2021.03.10 |
| [공공데이터포털 크롤링] data.go.kr 공공데이터포털 크롤링하기 (2) (0) | 2021.01.24 |
| [공공데이터포털 크롤링] data.go.kr 공공데이터포털 크롤링하기 (1) (0) | 2021.01.10 |
| python을 이용하여 디렉터리를 생성하고 파일 이동하기 (0) | 2020.06.17 |




댓글