공공데이터 포털
국가에서 보유하고 있는 다양한 데이터를『공공데이터의 제공 및 이용 활성화에 관한 법률(제11956호)』에 따라 개방하여 국민들이 보다 쉽고 용이하게 공유•활용할 수 있도록 공공데이터(Datase
www.data.go.kr
크롤링 하기
먼저 크롤링을 하기 위해서는 chrome의 Dev tools 사용을 추천한다. 솔직히 Dev tools를 자세히 알 필요는 없고 network tab에서 어떤 url을 request 해야 되는지 그리고 해당 태그의 순서 정도만 보면 된다.
크롤링 범위 정하기
크롤링할 대상이 정해졌으면 크롤링할 범위 또한 정해야한다. 공공데이터포털을 기준으로 보면 크게
- 파일 데이터
- 표준 데이터셋
- 오픈 API가 있다.
1. 파일 데이터는 csv, xlsx, pdf 등 파일을 다운받을 수 있다. 정확히는 모르겠지만 경험상 csv 파일이 제일 많다.
2. 표준 데이터셋은 파일 데이터의 집합이라고 보면된다. 주로 전국 단위의 데이터가 있으며 파일은 csv다.
그러면 가장 많은 자료가 csv이므로 공공데이터포털에 있는 csv 전체를 크롤링 해보자
크롤링 대상 규칙 찾기
공공데이터포털을 크롤링하기 위해서 BeautifulSoup을 사용한다. BeautifulSoup는 html parser다. 간단하게 설명하자면 html의 태그에 있는 정보를 얻을 수 있다.
우선 아래의 url에 접속해보자
접속해 보면 제목 처럼 보이는 파란글씨의 밑줄친 글자가 보인다.

파란글씨를 클릭해보자
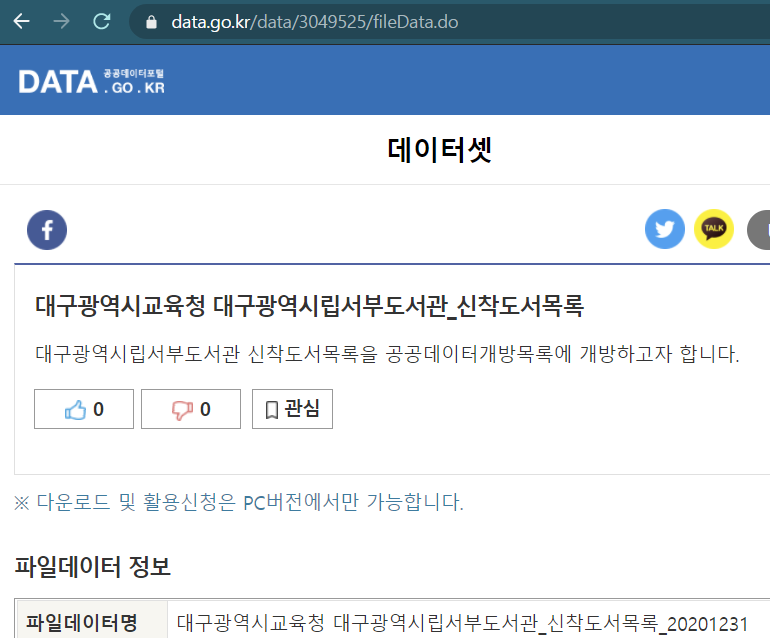
url 주소가 data.go.kr/data/3049525/fileData.do로 변경되었다. url을 보면 알 수 있듯 data.go.kr/data/{번호}/fileData.do라는 규칙을 가지고 있다. (다른 링크 클릭해보면 쉽게 알 수 있다.) 그럼 이제 저 번호를 이용할 수 있는지 확인을 해보자
확인 방법은 간단하다. 다운로드를 해보고 Dev tools에서 확인해보자
Dev tools의 Network tab을 활성화하고 파일을 다운받아보니 Query String Parameters에 이런 정보가 나온다.

url, publicDataDetailPk, publicDataPk, fileDetailSn 정보만 알면 파일을 다운 받을 수 있다. 확인방법은 주소창에서 검색해보면 된다.
어? json 결과가 나옵니다.
다운로드 하기 위해서는 좀 더 분석이 필요한거 같습니다. 다운로드 버튼에서 우클릭 검사를 누릅니다.
다운로드 버튼 클릭 시 onclick 이벤트로 js 함수가 실행되는것을 확인할 수 있습니다.

fn_fileDataDown()을 찾아보면 다음과 같습니다.

정리해 보자면 공공데이터포털에서 파일을 다운받기 위해서는
data.go.kr/data/3049525/fileData.do에서 숫자 부분 그리고 uddi가 필요합니다.
'python' 카테고리의 다른 글
| [공공데이터포털 크롤링] data.go.kr 공공데이터포털 크롤링하기 (4) (0) | 2021.03.10 |
|---|---|
| [공공데이터포털 크롤링] data.go.kr 공공데이터포털 크롤링하기 (3) (0) | 2021.01.24 |
| [공공데이터포털 크롤링] data.go.kr 공공데이터포털 크롤링하기 (2) (0) | 2021.01.24 |
| python을 이용하여 디렉터리를 생성하고 파일 이동하기 (0) | 2020.06.17 |
| pandas를 이용하여 csv row 추출하기 (0) | 2020.06.11 |



댓글