공공데이터포털에서 크롤링하여 국토관리, 사회복지 관련 자료를 다운받아 엑셀작업을 하는 임무를 부여받았다.
국토관리는 1,694건, 사회복지는 2,210건으로 크롤링 할때 데이터를 다 받으면 좋겠지만 다운로드 형식이 각각 csv, xlsx 가끔씩 hwp, zip 파일이 업로드 되어있다. 또 링크를 접소하여 해당 홈페이지에서 다운을 받아야하는 자료도 있기 때문에 공공데이터포털에서 리스트만 추출하였다.
약 3,900개의 자료를 다운받아서 해당 파일의 데이터를 보고 엑셀작업을 해야하는데 문제는 여기서 발생하였다. 각 데이터의 항목과 데이터예시를 엑셀에 저장해야하는데 이 작업이 시간이 많이 걸렸다. 반드시 코딩으로 시간 단축이 필요한 상황이였다.
예전 python으로 데이터를 추출하는 방법을 들은적이 있었다. 그래서 시도하게 되었다.
소스코드는 다음과 같다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
|
import pandas as pd
import numpy as np
import sys
import os
import glob
title = "86"
path = r'./test/case'
# 정렬 관련 옵션
# key=os.path.getctime 파일 생성일
# key=os.path.getatime 파일 최근 접근일
# key=os.path.getmtime 파일 최종 수정일
# key=os.path.getsize 파일 사이즈로 정렬
filenames = sorted(glob.glob(path + title + "/*.*"), key=os.path.getmtime)
# encoding='CP949' windows 파일 생성
tmp = []# 정렬된 csv 파일을 순서대로 읽기
for i in filenames:
# 한국어로 인코딩하기
# encoding 'CP949', 'euc_kr'은 한국어를 지원한다.
# https://docs.python.org/3/library/codecs.html#standard-encodings
data = pd.read_csv(i, encoding='CP949')
a = ""
# col name 읽어오기
for j in data.head(1):
a += j
a += " "
b = ""
# 내용 읽어오기
for j in data[1:2].values:
b += str(j)
b += " "
# tuple 형대로 배열에 저장
tmp.append([i, a, b])
# 배열을 data 형태로 저장하기
# option 중에 columns로 있다.
publicData = pd.DataFrame(data=tmp)
print(publicData)
publicData.to_csv('./항목' + title + '.csv', encoding='utf-8-sig')
|
cs |
디렉터리에 csv 파일을 다운 받아서 실행을 하면 다음과 같은 결과를 얻을 수 있다.

(2020-06-11 추가)
데이터 분리가 띄어쓰기로 되어있어 한 눈에 잘 안 들어온다는 요청사항이 있었다. 그래서 " | " 를 이용하여 분리하였다.
data.head()는 문자열로 취급하여 그냥 " | " 만 추가하면 되었다. 문제는 data[].values였다.
data.head() 처럼 같은 결과가 나오기를 기대하였지만 그렇지 않았다. 마치 하나의 문자열 처럼 작동하였다. 따라서 data[].values에서 for는 필요없게 되었고 이 문제를 어떻게 처리할까 이런 저런 기능들을 찾다가 귀찮아서 문자열로 변환하고 그냥 다 replace를 하였다. 기존 코드보다 속도는 많이 느려졌지만 서비스를 하는 코드도 아니고 ps 문제를 푸는것도 아니기 때문에 그냥 사용하기로 했다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
|
import pandas as pd
import numpy as np
import sys
import os
import glob
title = "44"
path = r'./test/case'
filenames = sorted(glob.glob(path + title + "/*.csv"), key=os.path.getmtime)
# encoding='CP949' windows 파일 생성
tmp = []
for i in filenames:
data = pd.read_csv(i, encoding='CP949')
a = "| "
for j in data.head(1):
a += j
a += " | "
b = str(data[1:2].values)
b = b.replace("' ", " | ")
b = b.replace(" '", " | ")
b = b.replace("[", "")
b = b.replace("]", "")
b = b.replace("'", "")
b = "| " + b + " |"
tmp.append([i, a, b])
publicData = pd.DataFrame(data=tmp)
print(publicData)
publicData.to_csv('./항목' + title + '.csv', encoding='utf-8-sig')
|
cs |
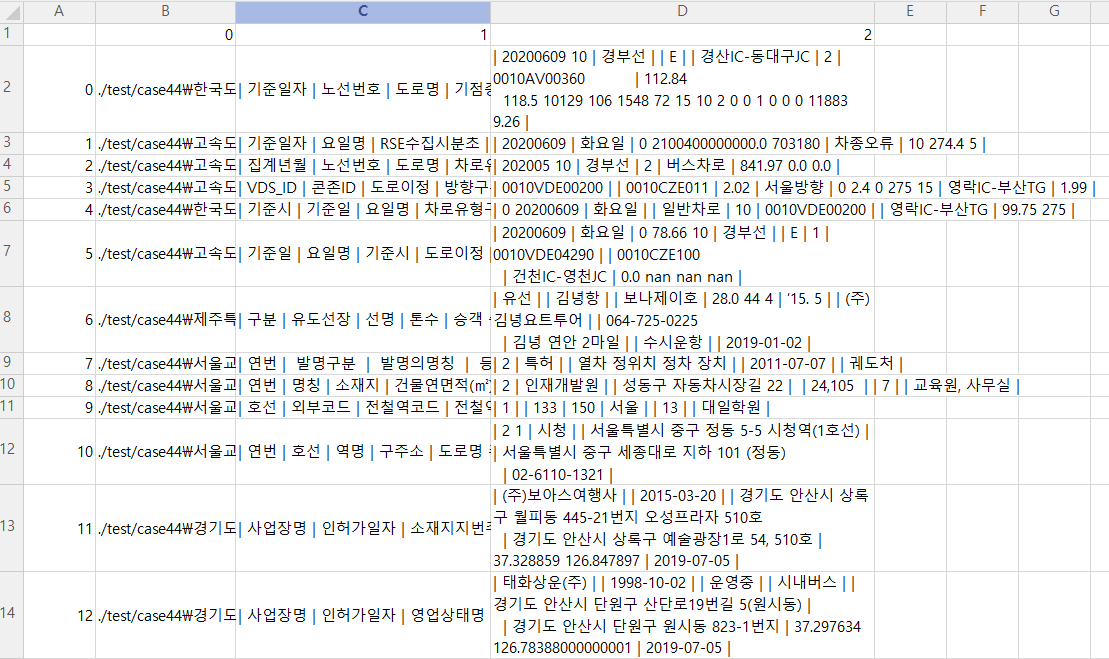
(2020-06-17 추가)
csv, excel을 따로 분리해서 작업하기가 번거로웠다. 애초에 분류하는 파일이 .csv와 excel 파일만 다운받는다. 따라서 .csv는 read_csv() 그 외는 read_excel()을 이용하기 위해 소스코드를 추가하였다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
|
import pandas as pd
import numpy as np
import sys
import os
import glob
title = "6"
path = r'./test/case'
filenames = sorted(glob.glob(path + title + "/*.*"), key=os.path.getmtime)
# encoding='CP949' windows 파일 생성
tmp = []
for i in filenames:
# 추가
if (i[-4:] == ".csv"):
data = pd.read_csv(i, encoding='CP949')
else:
data = pd.read_excel(i, encoding='CP949')
a = "| "
for j in data.head(1):
a += j
a += " | "
b = str(data[1:2].values)
b = b.replace("' ", " | ")
b = b.replace(" '", " | ")
b = b.replace("[", "")
b = b.replace("]", "")
b = b.replace("'", "")
b = "| " + b + " |"
tmp.append([i, a, b])
publicData = pd.DataFrame(data=tmp)
print(publicData)
publicData.to_csv('./항목' + title + '.csv', encoding='utf-8-sig')
|
cs |
'python' 카테고리의 다른 글
| [공공데이터포털 크롤링] data.go.kr 공공데이터포털 크롤링하기 (4) (0) | 2021.03.10 |
|---|---|
| [공공데이터포털 크롤링] data.go.kr 공공데이터포털 크롤링하기 (3) (0) | 2021.01.24 |
| [공공데이터포털 크롤링] data.go.kr 공공데이터포털 크롤링하기 (2) (0) | 2021.01.24 |
| [공공데이터포털 크롤링] data.go.kr 공공데이터포털 크롤링하기 (1) (0) | 2021.01.10 |
| python을 이용하여 디렉터리를 생성하고 파일 이동하기 (0) | 2020.06.17 |



댓글